HashMap
https://blog.csdn.net/ljf199701/article/details/106309417/
查找速度快,理想情况下时间复杂度为O(1)
- 在哈希表中插入一个元素的复杂度是O(1)
- 在无序数组中插入一个元素的复杂度是O(1)
- 访问数组中的第n个元素的复杂度是O(1)
- 访问链表中的第n个元素的复杂度是O(n)
HashMap的所有构造方法
| Constructor and Description |
|---|
HashMap()构造一个空的 HashMap ,默认初始容量(16)和默认负载系数(0.75)。 |
HashMap(int initialCapacity)构造一个空的 HashMap具有指定的初始容量和默认负载因子(0.75)。 |
HashMap(int initialCapacity, float loadFactor)构造一个空的 HashMap具有指定的初始容量和负载因子。 |
HashMap(Map<? extends K,? extends V> m)构造一个新的 HashMap与指定的相同的映射 Map 。 |
初始容量、加载因子与HashMap底层结构
容量有什么作用,加载因子有什么作用?
什么时候创建?
数组的作用、链表的作用
- Java中存储数据都需要容器
什么时候创建数组,什么时候形成链表
- 并不是在构造方法内创建的
- 实在
put方法中创建的- 为什么要在
put中创建
- 数组在内存中是一段连续的内存空间,如果创建了hashmap申请了空间,但是什么都不放,那就白白浪费了空间,所以在
put时才开辟空间怎么确定键值对Entry在数组中的位置
Entry键值对在数组中的位置重复了怎么办
- 如果存放的键值对在数组中位置相同,称为Hash冲突
如果数组中的每一个位置上都已经有Entry了怎么办?会发生什么?
- 会频繁的构成链表
- 因此提出了对数组进行
扩容- 当已使用的数组容量超过
初始容量 x 加载因子, 默认16 x 0.75 = 12时,对数组进行扩容
- HashMap的无参构造方法源代码
可以看到将负载因子设置为了默认负载因子值,并没有创建任何数组或链表
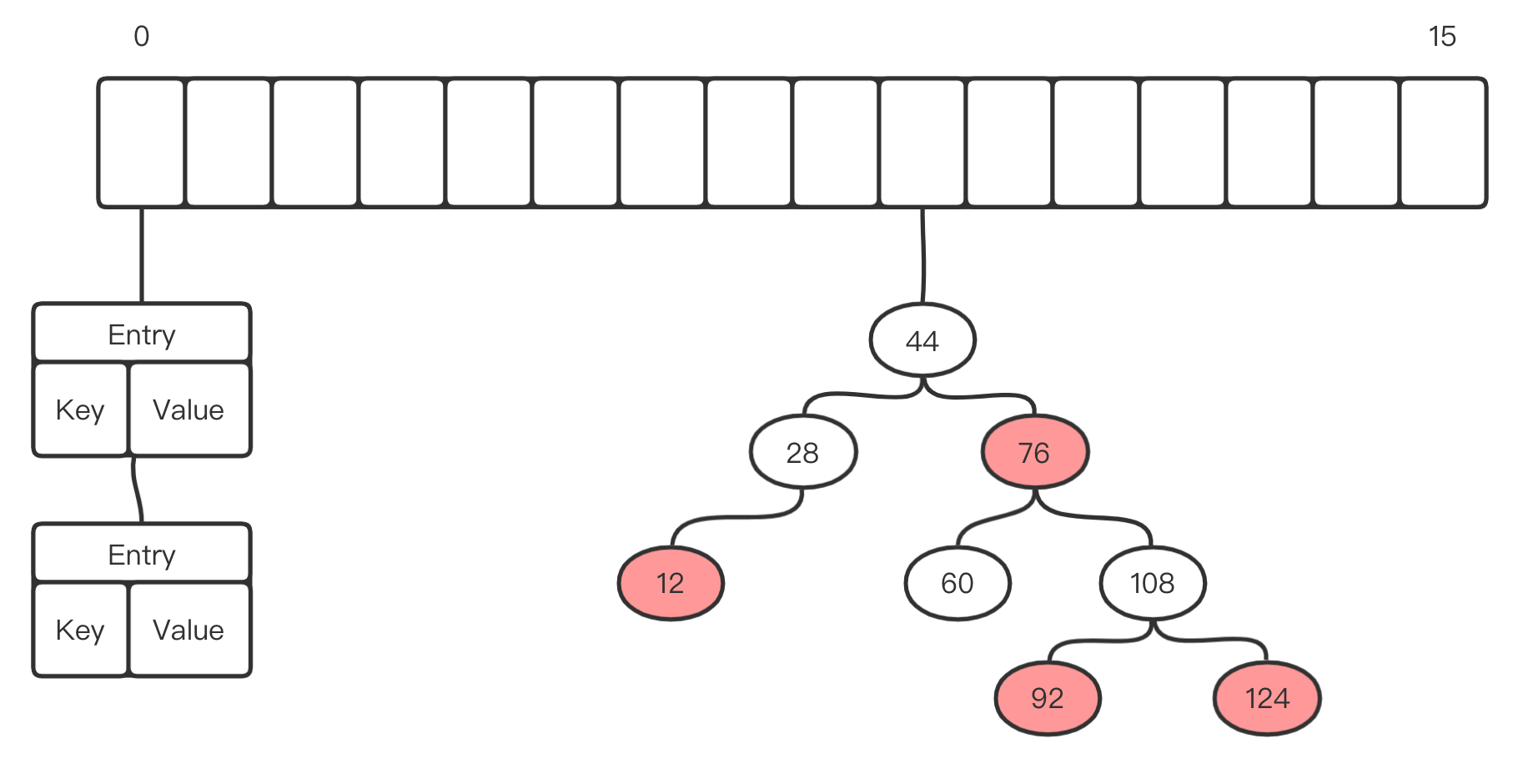
Hash冲突
- 如果存放的键值对在数组中位置相同,称为Hash冲突
- 则,在对应数组位置上,将重复Entry对象封装为一个链表
- 如果这个链表太长了,搜索效率就会因为链表这种结构而下降
- 默认,链表长达大于8,且数组长度大于64,转红黑树
put方法的源代码
向HashMap中存放数据,需要计算Hash值,计算键值对在数组中的位置,决定是否要进行扩容,并且HashMap的数组实际上是在put方法阶段被创建的
- 调用了
putVal() putVal()调用了hash()哈希方法 [用于确定Entry在数组中的位置,具体请看《怎么确定Entry在数组中定位置》],哈希方法返回了一个int值- 判断数组是否存在or数组长度为0,如果不存在或长度为0就调用
resize()根据初始容量得到一个数组对象,并将其长度赋给n - 使用数组最大下标(n-1)作为低位掩码取hash低位作为数组下标
- 判断数组对应下标位置上有没有Entry元素,可能出现三种情况
- 位置上啥也没有,是个null,直接newNode,创建一个Entry节点放进去
- 位置上有个Entry,要涉及链表操作
- 位置上是个红黑树,涉及到平衡二叉树操作
- tab节点数组
transient表示临时,主要涉及到Java序列化和安全性,使用后变量不会被持久化,关于它的具体内容请看transient关键字详解
- 用于转红黑树的treeifyBin()方法
- 如果key冲突,put方法返回被覆盖的旧值
初始容量
源代码
- 使用位操作定义,二进制
0001左移4下, 变为二进制0001 0000等于十进制16 - 注释中写到,初始容量必须为
2的幂
最大容量
- 最大容量为
2的30次幂 - 必须为小于
2的30次幂的一个2的次幂
加载因子——控制扩容阈值
怎么确定Entry在数组中的位置——hash()
- 如果
key为null,则直接将hash值设定为0 - 否则计算hash code,调用的是Object的hashCode方法,计算完后想有无符号移动16位,并且取高位 -> 再和原始hash进行异或运算,返回一个
int值 - 这段计算Hash code的代码为的是实现
扰动函数,降低碰撞几率。具体请看[JDK1.8中HashMap中的hash方法的底层原理是什么] - 返回的并不是entry在数组中的下标,因为这个方法并不知道数组的具体长度
- 最终确定位置要看
put()方法,具体请看put方法,结论为: 使用数组的总长度n,减去1,即n-1即数组的最大下标,与hash值做按位与运算得到下标(n-1) & hash - 这也正好解释了为什么HashMap的数组长度要取
2的整次幂。因为这样(数组长度-1)正好相当于一个“低位掩码”。- 2的次幂用二进制书写的话,形式为
0000 0001、0000 0010、0000 0100这样的one-hot编码,即总是只有一位为1,剩下全为0 - 2的次幂的二进制表示,只要-1,就会变为
0000 0000、0000 0001、0000 0011,这样的编码,从高位全为0,从某一位开始全变成1 - 当一个值用二进制表示时,值的变化更多的会反映在二进制低位上的变化,高位变化比较少,因为高位代表的值很大,低四位则是1、2、4、8这样的小值,经常出现变动以达到凑成某个数的效果。这样的值和
1111 1111这种全1的二进制做与运算(用在putVal中的计算数组下标的代码中),运算结果能最大程度反映hash值的变化,降低碰撞概率。 - 这段hash方法的return语句中,Object方法返回的原始hash int值高位通常都是1,因此右移16位后,变成一个低位全是1的二进制数,同原始hash做异或运算,也能最大程度上反映hash值的变化,降低碰撞概率
- 2的次幂用二进制书写的话,形式为
hashmap能不能存 key=null, value=null
能
如果key为null,HashMap的hash方法直接将其hash值设置为0
扩容
如果数组中的每一个位置上都已经有Entry了怎么办?会发生什么?
- 会频繁的构成链表
- 因此提出了对数组进行
扩容 - 当已使用的数组容量超过
初始容量 x 加载因子, 默认16 x 0.75 = 12时,对数组进行扩容,总是扩容为原来的2倍,除非达到最大数组容量 - 扩容的目的:减少Hash冲突,提高查询效率
resize()方法源码
JDK1.7链表头插法改为JDK1.8链表尾插法
1.7新元素在链表头部插入,在HashMap扩容时,如果是并发环境,可能会在链表元素逆序时,产生循环引用,即前一个指向后一个,后一个又指向前一个,形成环链,导致并发环境下出现死锁
JDK1.8引入红黑树
- 因为链表太长时,时间复杂度从常数阶
O(1)增长到线性阶O(n)- 引入红黑树复杂度控制在
O(logn)- 当数组长度大于64,且链表长度大于8,将链表转为红黑树
- 当链表长度小于6时,转回链表
- 最小树容量为64
HashMap 和 Hashtable 的区别
HashMap 允许 key 和 value 为 null,Hashtable 不允许。
HashMap 的默认初始容量为 16,Hashtable 为 11。
HashMap 的扩容为原来的 2 倍,Hashtable 的扩容为原来的 2 倍加 1。
HashMap 是非线程安全的,Hashtable是线程安全的。
HashMap 的 hash 值重新计算过,Hashtable 直接使用 hashCode。
HashMap 去掉了 Hashtable 中的 contains 方法。
HashMap 继承自 AbstractMap 类,Hashtable 继承自 Dictionary 类。
ConcurrentHashMap
分段锁实现线程安全——ConcurrentHashMap原理解析
- ConcurrentHashMap不允许
null作为key或者value,会抛出空指针异常
HashTable是线程安全的,为什么不直接使用HashTable?
- HashTable基于synchronized进行方法同步,读、写都是用了synchronized,插入时不能读,读取时不能写,因为HashTable锁的是整个集合,全表锁,多线程情况下效率极低
- 于是,ConcurrentHashMap使用了分段锁技术,采用细粒度锁,只锁集合的一部分
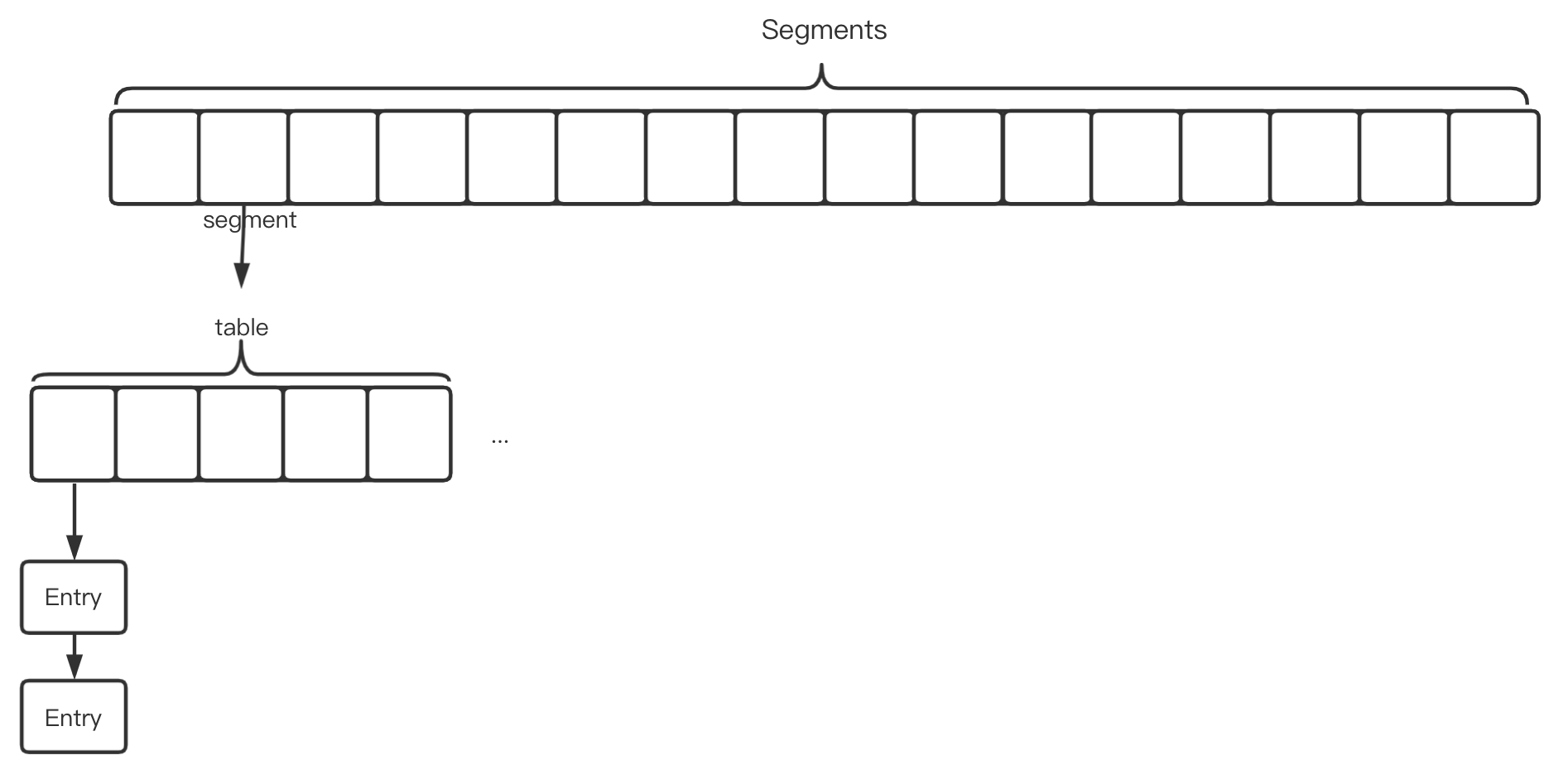
JDK1.5 —— Segment级可重入锁
- 由一个
segments数组构成,里面存放着segment,每个segment里面是一个数组,数组上的每个元素是Entry对象构成的链表- 每个
segment具有一把锁,当一个线程占用一个segment,只会锁当前的segment,其他的segment依然可以被访问- 默认16个
segment
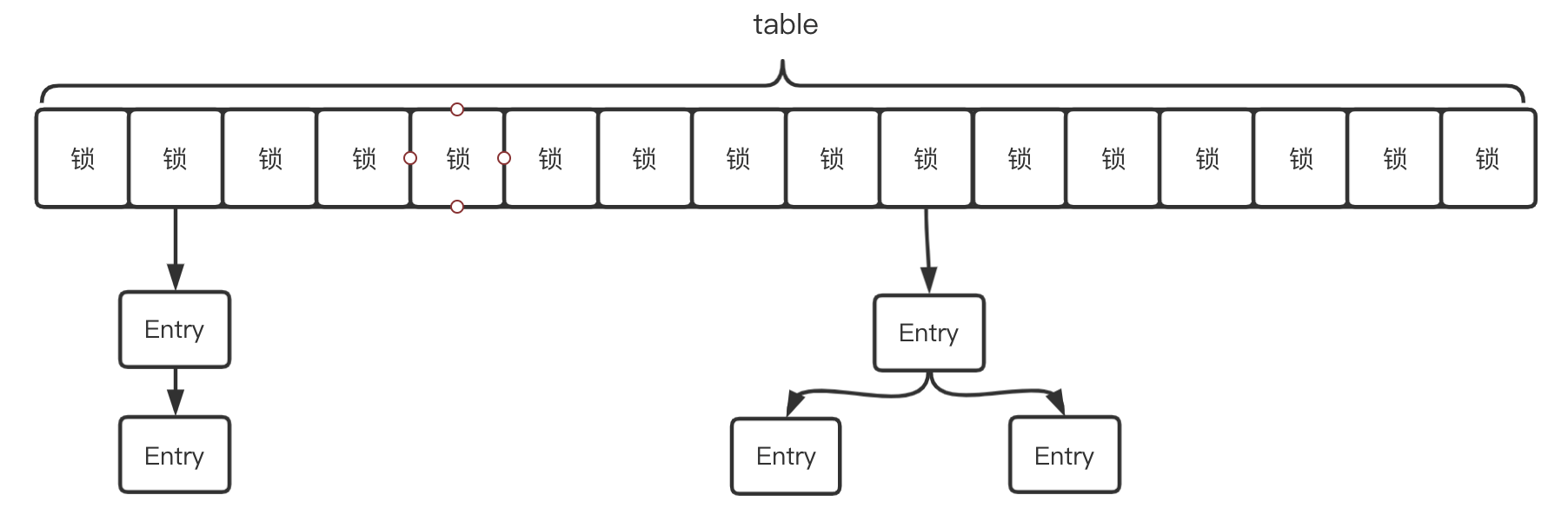
JDK1.8——链表头CAS+synchronized细粒度锁
- 取消了
Segments,结构与JDK1.8 HashMap相同- 采用CAS+synchronized,锁链表头结点或红黑树根结点
- 只要hash不冲突,就不会产生并发
- 相比1.5的实现,锁粒度更细,效率更高
- put方法
分析如何利用CAS和synchronized进行高效同步数据更新
- 判断Node[]数组是否初始化,没有则进行初始化操作
- 通过hash定位Node[]数组的索引坐标,是否有Node节点,如果没有则使用CAS进行添加(链表的头结点),添加失败则进入下次循环。
- 检查到内部正在扩容,如果正在扩容,就帮助它一块扩容。
- 如果f!=null,则使用synchronized锁住f元素(链表/红黑二叉树的头元素) 4.1 如果是Node(链表结构)则执行链表的添加操作。 4.2 如果是TreeNode(树型结果)则执行树添加操作。
- 判断链表长度已经达到临界值8 就需要把链表转换为树结构。
总结:
JDK8中的实现也是锁分离的思想,它把锁分的比segment(JDK1.5)更细一些,只要hash不冲突,就不会出现并发获得锁的情况。
它首先使用无锁操作CAS插入头结点,如果插入失败,说明已经有别的线程插入头结点了,再次循环进行操作。
如果头结点已经存在,则通过synchronized获得头结点锁,进行后续的操作。性能比segment分段锁又再次提升
面试题
- HashMap线程安全问题发生在哪个阶段?设计一个方案验证HashMap的线程安全问题
- 准备多个线程
- 同时访问同一个HashMap
- HashMap能不能存null,null
- HashMap扩容大小为什么总是2的次幂
- HashMap底层为什么要使用异或运算
- HashMap如何确定键值对位置,如何解决Hash冲突
- HashMap加载因子为什么为0.75,如果改为1呢
- HashMap与ConcurrentHashMap的区别
- ConcurrentHashMap是如何实现线程安全的
- 分段锁
- HashMap会缩容吗
- 不会,反复横跳反而是一种浪费资源的操作
- 曾经扩容上去了,就说明这个场景确实会用到很大的容量
- 可以手动缩(略)
- 扩容后,节点重 hash 为什么只可能分布在 “原索引位置” 与 “原索引 + oldCap 位置”?