NoSQL概述
为什么要使用非关系型数据库NoSQL?
- 单机MySQL年代
2020年已经是大数据时代,一般的数据库已经无法进行分析处理了
- 数据量太大,一个机器放不下
- 数据库索引,MySQL B+树,数据太多,单个计算机内存放不下
- 访问量(读写混合),逼近单台服务器承受极限
- Memcached(缓存)+MySQL+垂直拆分(读写分离)
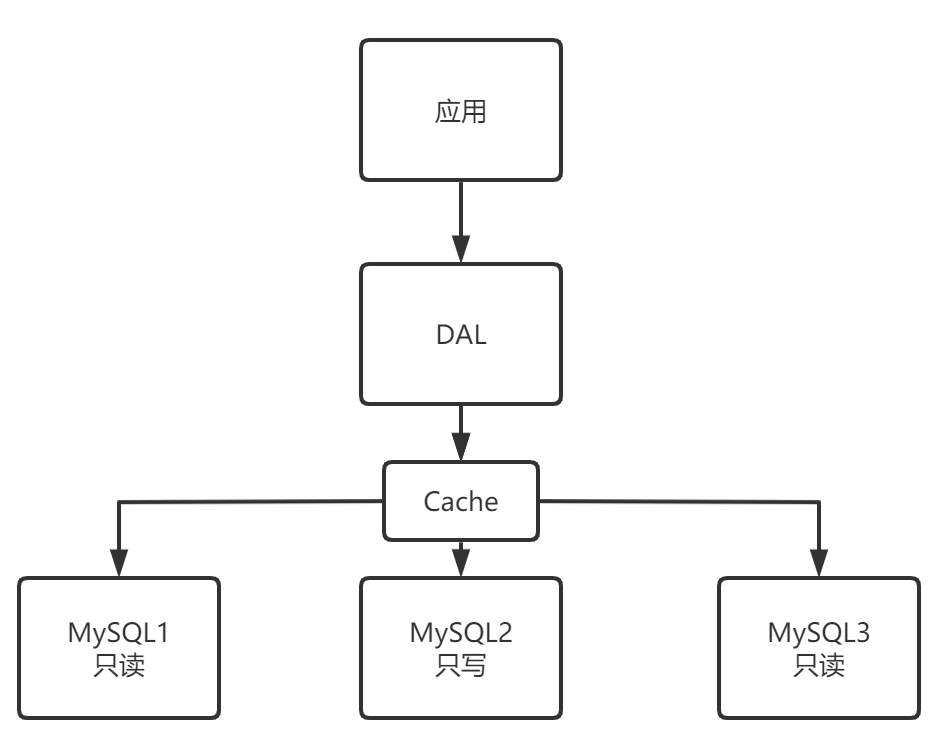
网站大部分时候都在执行查询操作,这样会造成频繁访问数据库,于是产生了缓存,相同的查询直接走缓存,减轻数据库的访问压力,保证效率
- 分库分表、水平拆分(MySQL集群)
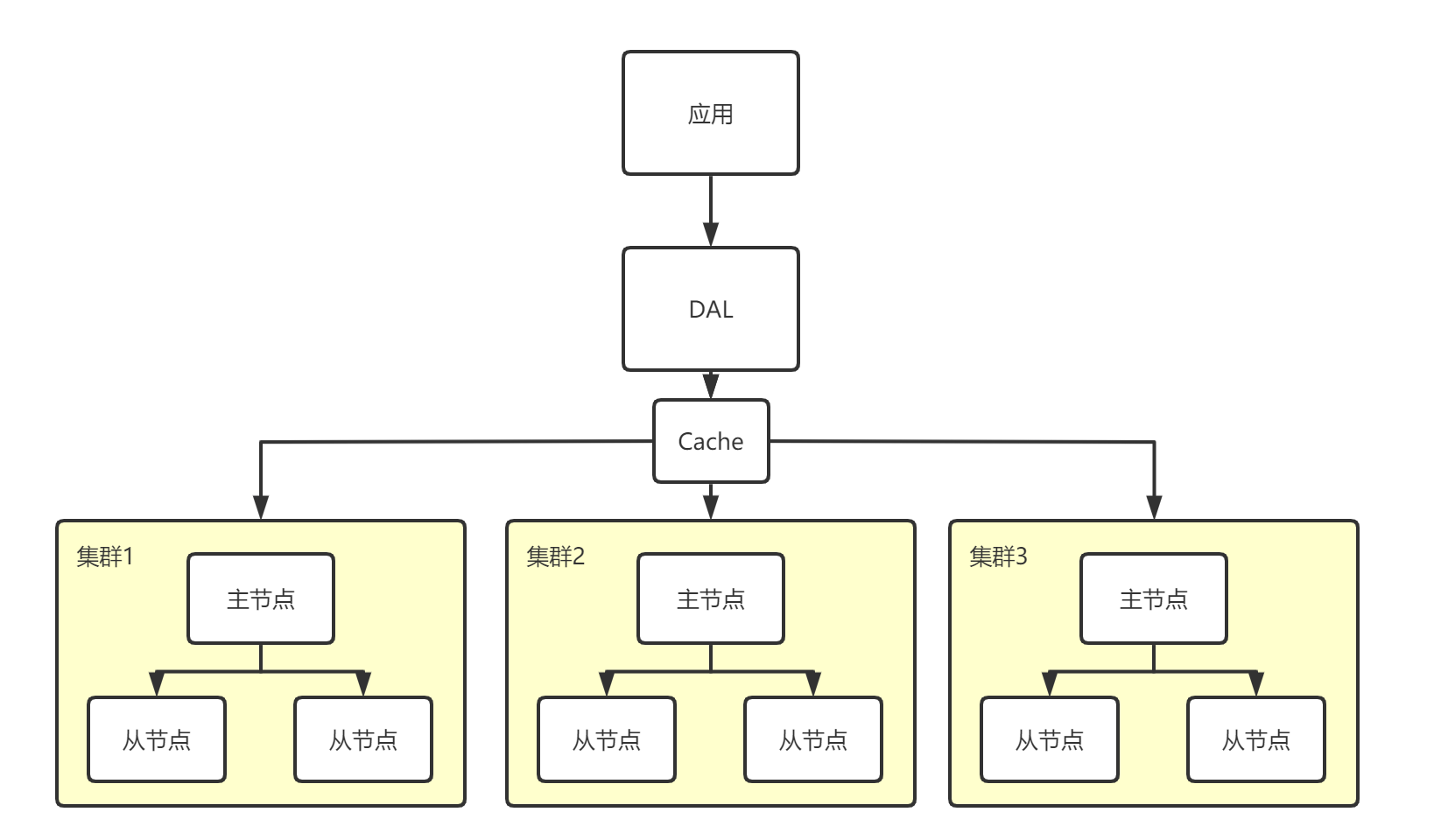
本质:数据库(读、写)
- MyISAM引擎:表锁,十分影响效率,高并发下会出现严重问题
- InnoDB引擎:行锁
当前:
MySQL等关系型数据库不够用了,数据量很大,变化很快
如果有一种数据库专门处理较大的数据,例如博客,图片,视频,那么MySQL的压力就会变小
产生了多种形式的存储方式,,例如JSON -> BSOM(二进制JSON,MySQL难以应付频繁和大幅度的修改
当今企业架构分析
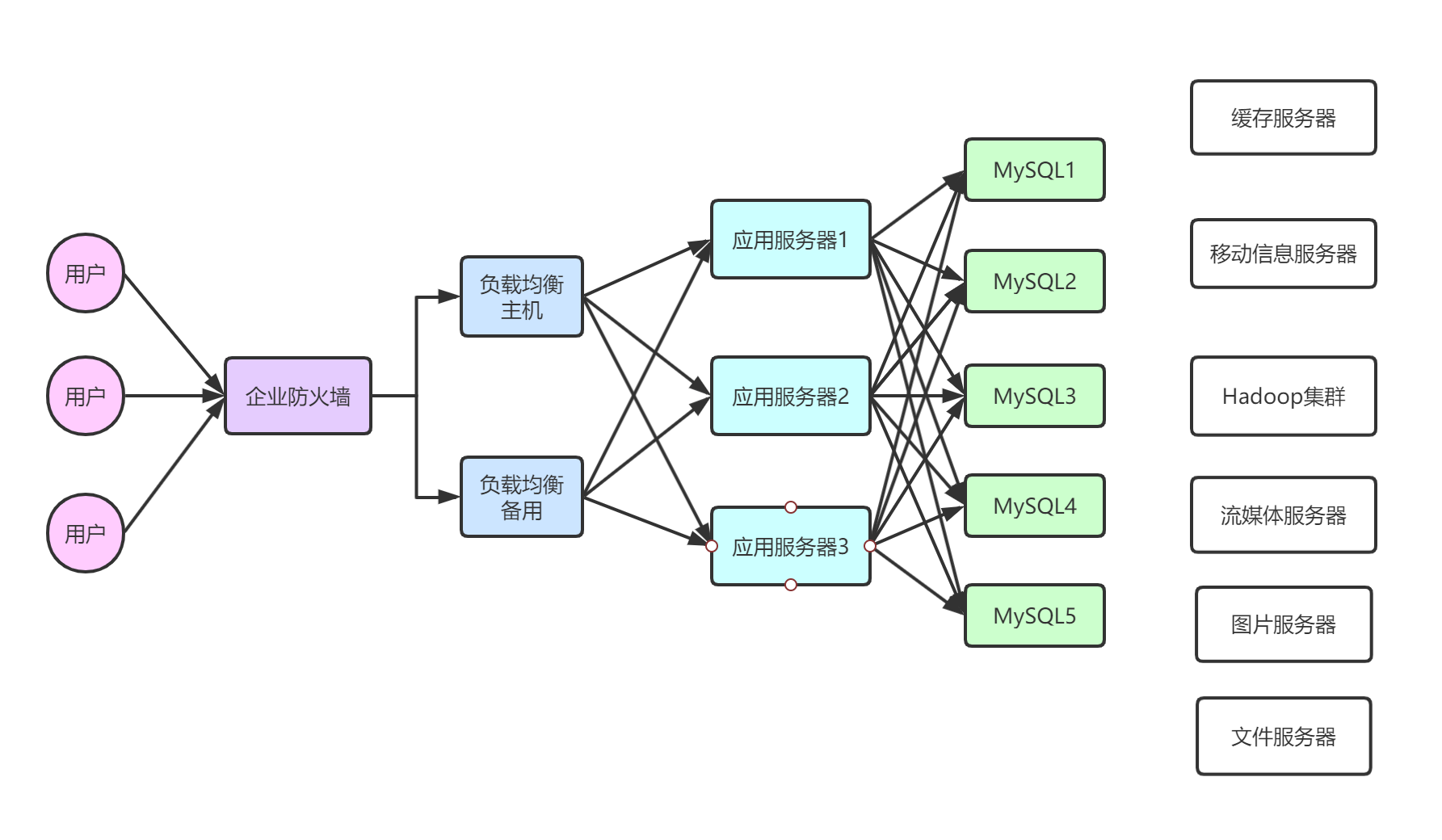
为什么使用NoSQL
用户个人信息,社交网络,地理位置等因素造成数据、用户日志等爆炸式增长
NoSQL数据库可以很好的处理以上情况
什么是NoSQL
NoSQL -> Not Only SQL
泛指非关系型数据库,传统关系型数据库难以应付大规模高并发场景,NoSQL在当今大数据环境下发展的十分迅速,Redis是其中发展最快的,是我们当下必须掌握的一项技术
很多应用数据不需要固定格式(行、列、表),不需要多余的操作就可以横向扩展(多机器集群)
NoSQL的特点
大数据量、高性能 Redis一秒写入8万次,读取11万次 NoSQL的缓存记录级,是一种细粒度的缓存
数据类型是多样的
五种基本数据类型
String、List、Set、Hash、Zset三种特殊数据类型
geo、hyperloglog、bitmap
不需要实现设计数据库,随区随用
传统RDBMS关系型数据库与NoSQL的区别
| 关系型数据库 | 非关系数据库 |
|---|---|
| SQL | NoSQL |
| 数据和关系都存在单独的表中 | 不仅仅是数据 |
| 操作、数据定义语言 | 没有固定查询语言 |
| 严格的一致性 | 键值对、列、文档、图形存储 |
| 基础事务 | 最终一致性 |
| CAP定理和BASE、异地多活 | |
| 高性能、高可用、高可扩 |
了解:3V+3高
- 大数据时代的3V:主要描述问题
- 海量Volume
- 多样Variety
- 实时Velocity
- 大数据时代的3高:主要是对程序的要求
- 高并发
- 高可拓展
- 高性能
实践中:NoSQL+RDBMS
阿里巴巴架构演进分析
php -> java -> EJP -> Spring+IBatis -> 分布式
敏捷开发、极限编程
商品基本信息
名称、价格、商家信息
关系型数据库就可以解决、阿里自己修改的
MySQL(《阿里云的这群疯子》)商品的描述、评论
文档行数据库,
MongoDB图片
分布式文件系统
FastDFS淘宝自己的
TFSGFSHadoop
HDFS阿里云
oss商品关键字(用于搜索)
搜索引擎:
solr、ElasticSearch、ISearch(多隆)商品热门波段信息
内存数据库:
Redis、Tair商品的交易、外部支付接口
第三方应用
一张网页背后的技术并不是那么简单的
大厂产品面临的问题:
- 数据类型太多
- 数据源太多,经常重构
- 数据要改造,大面积改动
解决方案:统一数据服务层
UDSL
- 屏蔽所有数据库的差异
- 大厂独有的自研技术
NoSQL的四大分类
KV键值对
- 新浪:Redis
- 美团:Redis+Tair
- 阿里、百度:Redis+memcatch
文档型数据库(BSON)
- MongoDB(一般必须掌握)
基于分布式文件存储的数据库,使用CPP编写,主要用来存储大量的文档
- MongoDB是一个介于关系型数据库和非关系数据库之间的产品,MongoDB是非关系型数据库中功能最丰富,最想关系型数据库的
- ConthDB
列存储数据库
- HBase
- 分布式文件系统
图数据库(拓扑型)——用于存储关系拓扑结构
社交网络关系、社交推荐、广告推荐
- Neo4j
- InfoGrid
| 分类 | Examples举例 | 典型应用场景 | 数据模型 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 键值(key-value) | Tokyo Cabinet/Tyrant, Redis, Voldemort, Oracle BDB | 内容缓存,主要用于处理大量数据的高访问负载,也用于一些日志系统等等。 | Key 指向 Value 的键值对,通常用hash table来实现 | 查找速度快 | 数据无结构化,通常只被当作字符串或者二进制数据 |
| 列存储数据库 | Cassandra, HBase, Riak | 分布式的文件系统 | 以列簇式存储,将同一列数据存在一起 | 查找速度快,可扩展性强,更容易进行分布式扩展 | 功能相对局限 |
| 文档型数据库 | CouchDB, MongoDb | Web应用(与Key-Value类似,Value是结构化的,不同的是数据库能够了解Value的内容) | Key-Value对应的键值对,Value为结构化数据 | 数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构 | 查询性能不高,而且缺乏统一的查询语法。 |
| 图形(Graph)数据库 | Neo4J, InfoGrid, Infinite Graph | 社交网络,推荐系统等。专注于构建关系图谱 | 图结构 | 利用图结构相关算法。比如最短路径寻址,N度关系查找等 | 很多时候需要对整个图做计算才能得出需要的信息,而且这种结构不太好做分布式的集群 |